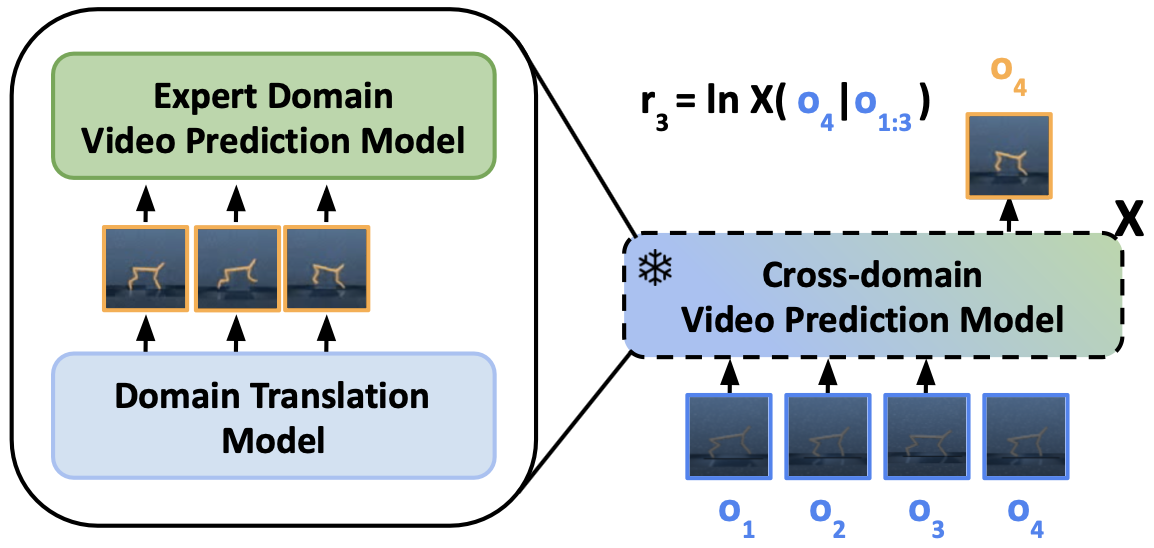
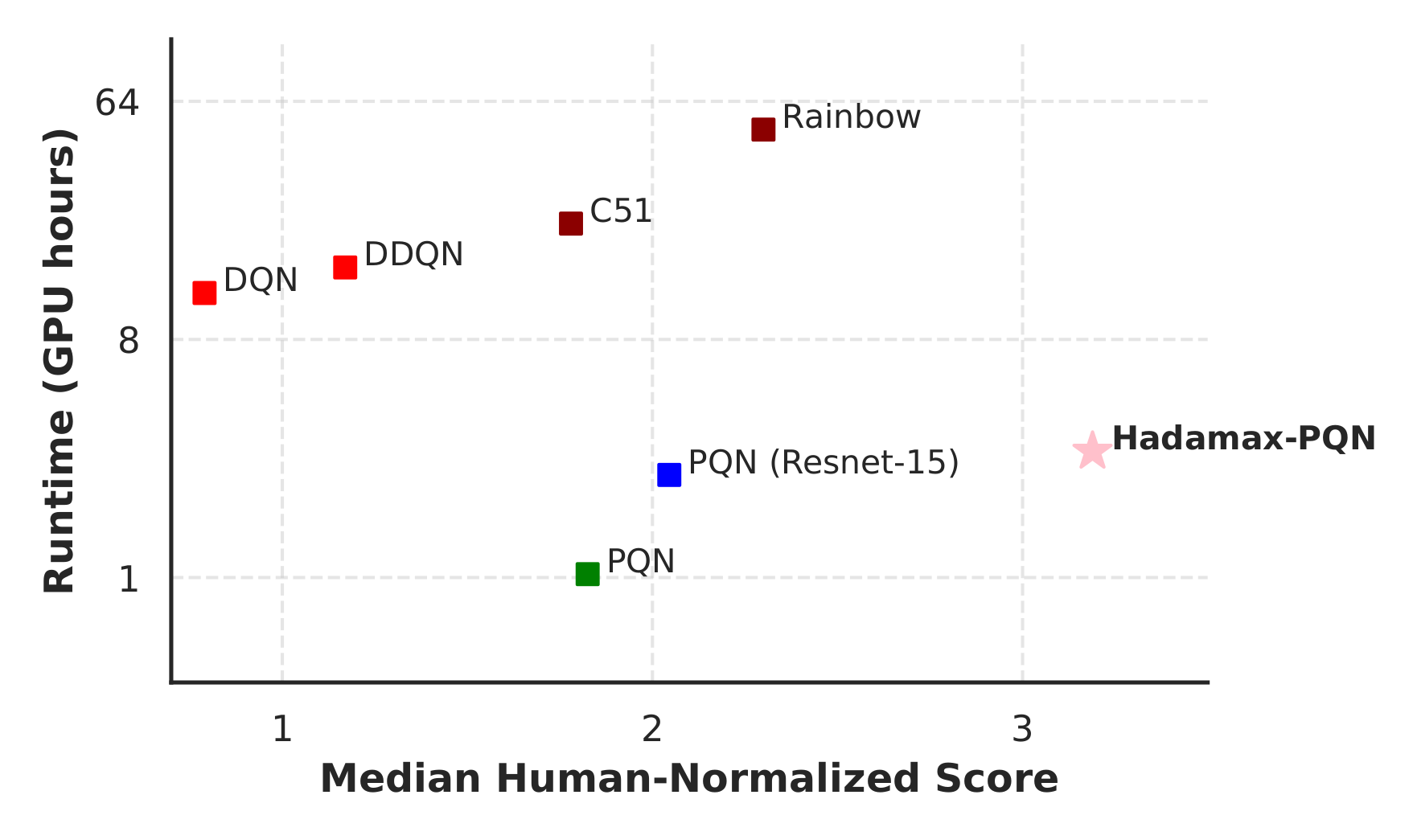
I am a postdoc at VU Amsterdam working with Vincent François-Lavet. I received my PhD from Leiden University where I worked with Thomas Moerland, Mike Preuss, and Aske Plaat. I got my master degree at Leiden University in 2020, and bachelor degree at BLCU, China, in 2018.
I am interested in artificial intelligence and how it can support decision-making. To that end, I research reinforcement learning and its applications in both virtual environments (e.g. video games and robitics) and real-world domains (e.g. healthcare and LLMs).
I co-host BeNeRL seminar and review.
Contact: z.yang(at)liacs.leidenuniv.nl
Google Scholar |
LinkedIn |
Twitter |
Github |
CV